Pandas 是基于 NumPy 的一个开源 Python 库,它被广泛用于快速分析数据,以及数据清洗和准备等工作。它的名字来源是由“ Panel data”(面板数据,一个计量经济学名词)两个单词拼成的。简单地说,你可以把 Pandas 看作是 Python 版的 Excel。
我喜欢 Pandas 的原因之一,是因为它很酷,它能很好地处理来自一大堆各种不同来源的数据,比如 Excel 表格、CSV 文件、SQL 数据库,甚至还能处理存储在网页上的数据。
话不多说,让我们开始吧!
安装 Pandas
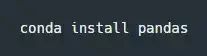
如果你已经安装了 Anaconda,你可以很方便地在终端或者命令提示符里输入命令安装 Pandas:
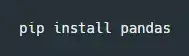
如果你还没安装 Anaconda,你也可以用 Python 自带的包管理工具 pip 来安装:
Pandas 数据结构
Series 是一种一维数组,和 NumPy 里的数组很相似。事实上,Series 基本上就是基于 NumPy 的数组对象来的。和 NumPy 的数组不同,Series 能为数据自定义标签,也就是索引(index),然后通过索引来访问数组中的数据。
创建一个 Series 的基本语法如下:

上面的 data 参数可以是任意数据对象,比如字典、列表甚至是 NumPy 数组,而 index参数则是对 data 的索引值,类似字典的 key。
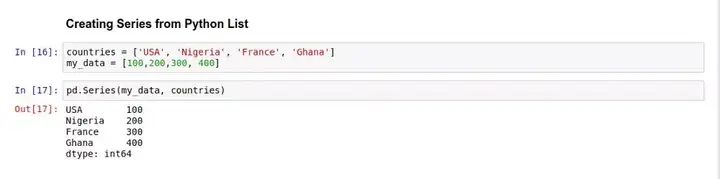
下面这个例子里,将创建一个 Series 对象,并用字符串对数字列表进行索引:
注意:请记住, index 参数是可省略的,你可以选择不输入这个参数。如果不带 index参数,Pandas 会自动用默认 index 进行索引,类似数组,索引值是 [0, ..., len(data) - 1] ,如下所示:
从 NumPy 数组对象创建 Series:
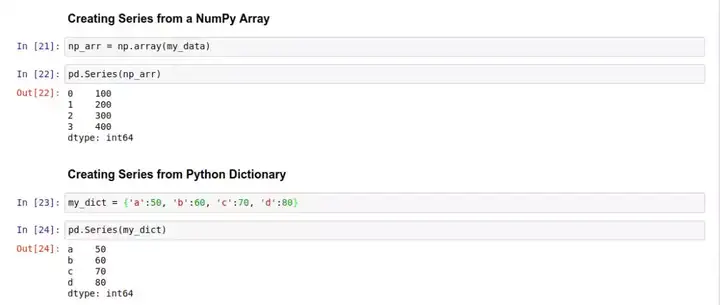
从 Python 字典对象创建 Series:
如上图的 out[24] 中所示,如果你从一个 Python 字典对象创建 Series,Pandas 会自动把字典的键值设置成 Series 的 index,并将对应的 values 放在和索引对应的data 里。
和 NumPy 数组不同,Pandas 的 Series 能存放各种不同类型的对象。
从 Series 里获取数据
访问 Series 里的数据的方式,和 Python 字典基本一样:

对 Series 进行算术运算操作
对 Series 的算术运算都是基于 index 进行的。我们可以用加减乘除(+ - * /)这样的运算符对两个 Series 进行运算,Pandas 将会根据索引 index,对响应的数据进行计算,结果将会以浮点数的形式存储,以避免丢失精度。
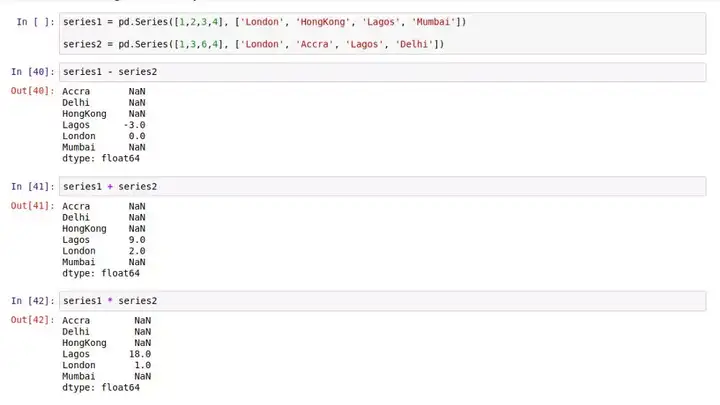
如上,如果 Pandas 在两个 Series 里找不到相同的 index,对应的位置就返回一个空值NaN。
DataFrames
Pandas 的 DataFrame(数据表)是一种 2 维数据结构,数据以表格的形式存储,分成若干行和列。通过 DataFrame,你能很方便地处理数据。常见的操作比如选取、替换行或列的数据,还能重组数据表、修改索引、多重筛选等。
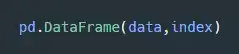
构建一个 DataFrame 对象的基本语法如下:
举个例子,我们可以创建一个 5 行 4 列的 DataFrame,并填上随机数据:
看,上面表中的每一列基本上就是一个 Series ,它们都用了同一个 index。因此,我们基本上可以把 DataFrame 理解成一组采用同样索引的 Series 的集合。
下面这个例子里,我们将用许多 Series 来构建一个DataFrame:

以及用一个字典来创建 DataFrame:
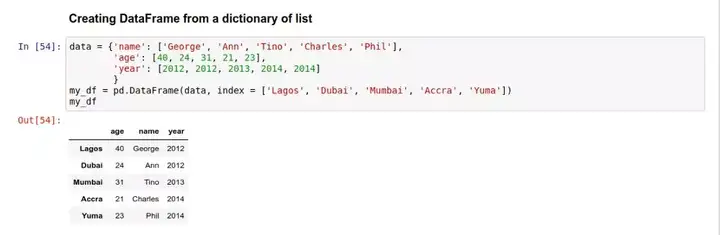
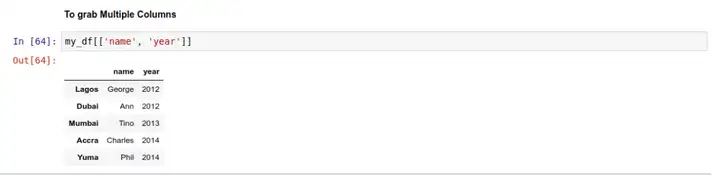
获取 DataFrame 中的列
要获取一列的数据,还是用中括号 [] 的方式,跟 Series 类似。比如尝试获取上面这个表中的 name 列数据:

因为我们只获取一列,所以返回的就是一个 Series。可以用 type() 函数确认返回值的类型:

如果获取多个列,那返回的就是一个 DataFrame 类型:
向 DataFrame 里增加数据列
创建一个列的时候,你需要先定义这个列的数据和索引。举个栗子,比如这个 DataFrame:

增加数据列有两种办法:可以从头开始定义一个 pd.Series,再把它放到表中,也可以利用现有的列来产生需要的新列。比如下面两种操作:
定义一个 Series ,并放入 'Year' 列中:
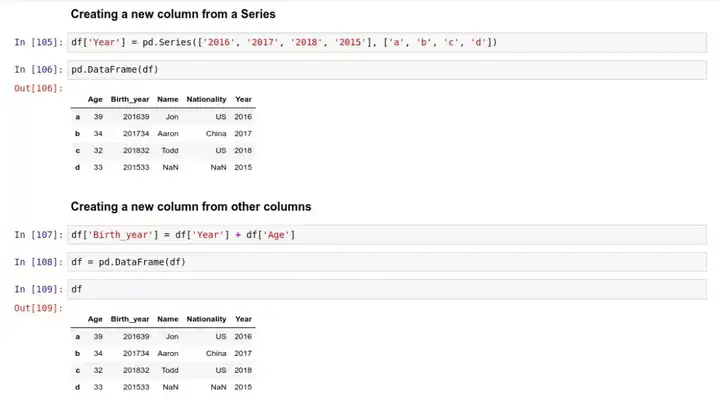
从现有的列创建新列:
从 DataFrame 里删除行/列
想要删除某一行或一列,可以用 .drop() 函数。在使用这个函数的时候,你需要先指定具体的删除方向,axis=0 对应的是行 row,而 axis=1 对应的是列 column 。
删除 'Birth_year' 列:
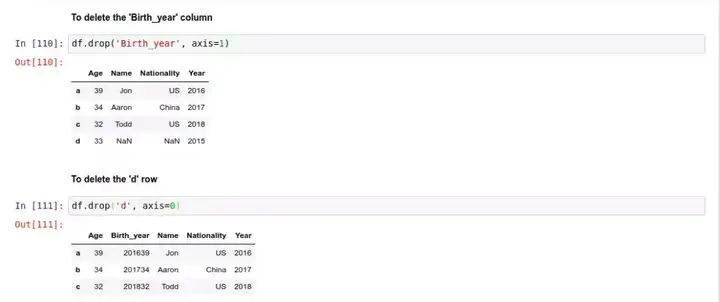
删除 'd' 行:
请务必记住,除非用户明确指定,否则在调用 .drop() 的时候,Pandas 并不会真的永久性地删除这行/列。这主要是为了防止用户误操作丢失数据。
你可以通过调用 df 来确认数据的完整性。如果你确定要永久性删除某一行/列,你需要加上 inplace=True 参数,比如:

获取 DataFrame 中的一行或多行数据
要获取某一行,你需要用 .loc[] 来按索引(标签名)引用这一行,或者用 .iloc[] ,按这行在表中的位置(行数)来引用。
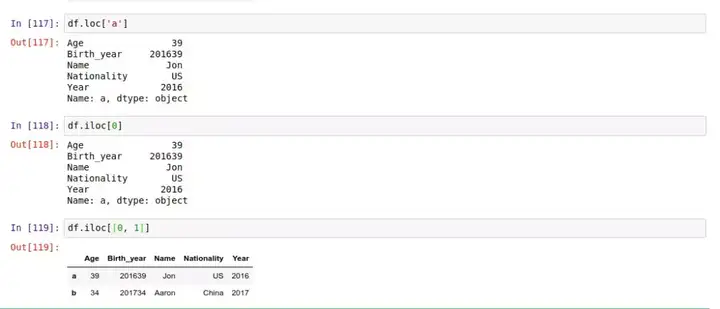
同时你可以用 .loc[] 来指定具体的行列范围,并生成一个子数据表,就像在 NumPy 里做的一样。比如,提取 'c' 行中 'Name’ 列的内容,可以如下操作:

此外,你还可以制定多行和/或多列,如上所示。
条件筛选
用中括号 [] 的方式,除了直接指定选中某些列外,还能接收一个条件语句,然后筛选出符合条件的行/列。比如,我们希望在下面这个表格中筛选出 'W'>0 的行:

如果要进一步筛选,只看 'X' 列中 'W'>0 的数据:

类似的,你还可以试试这样的语句 df[df['W']>0][['X','Y']] ,结果将会是这样:

上面那行相当于下面这样的几个操作连在一起:

你可以用逻辑运算符 &(与)和 |(或)来链接多个条件语句,以便一次应用多个筛选条件到当前的 DataFrame 上。举个栗子,你可以用下面的方法筛选出同时满足 'W'>0 和'X'>1 的行:

重置 DataFrame 的索引
如果你觉得当前 DataFrame 的索引有问题,你可以用 .reset_index() 简单地把整个表的索引都重置掉。这个方法将把目标 DataFrame 的索引保存在一个叫 index 的列中,而把表格的索引变成默认的从零开始的数字,也就是 [0, ..., len(data) - 1]。比如下面这样:
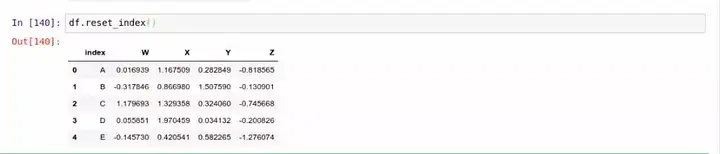
和删除操作差不多,.reset_index() 并不会永久改变你表格的索引,除非你调用的时候明确传入了 inplace 参数,比如:.reset_index(inplace=True)
设置 DataFrame 的索引值
类似地,我们还可以用 .set_index() 方法,将 DataFrame 里的某一列作为索引来用。比如,我们在这个表里新建一个名为 "ID" 的列:
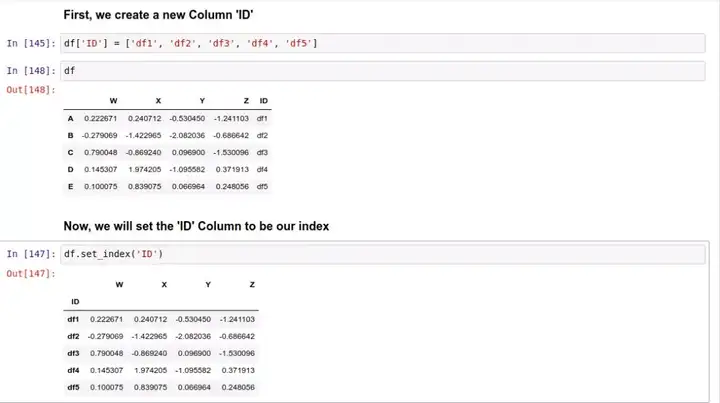
然后把它设置成索引:
注意,不像 .reset_index() 会保留一个备份,然后才用默认的索引值代替原索引,.set_index() 将会完全覆盖原来的索引值。
多级索引(MultiIndex)以及命名索引的不同等级
多级索引其实就是一个由元组(Tuple)组成的数组,每一个元组都是独一无二的。你可以从一个包含许多数组的列表中创建多级索引(调用 MultiIndex.from_arrays ),也可以用一个包含许多元组的数组(调用 MultiIndex.from_tuples )或者是用一对可迭代对象的集合(比如两个列表,互相两两配对)来构建(调用MultiIndex.from_product )。
下面这个例子,我们从元组中创建多级索引:

最后这个 list(zip()) 的嵌套函数,把上面两个列表合并成了一个每个元素都是元组的列表。这时 my_index 的内容是这样的:[('O Level', 21), ('O Level', 22), ('O Level', 23), ('A Level', 21), ('A Level', 22), ('A Level', 23)]
接下来,我们调用 .MultiIndex.from_tuples(my_index) 生成一个多级索引对象:
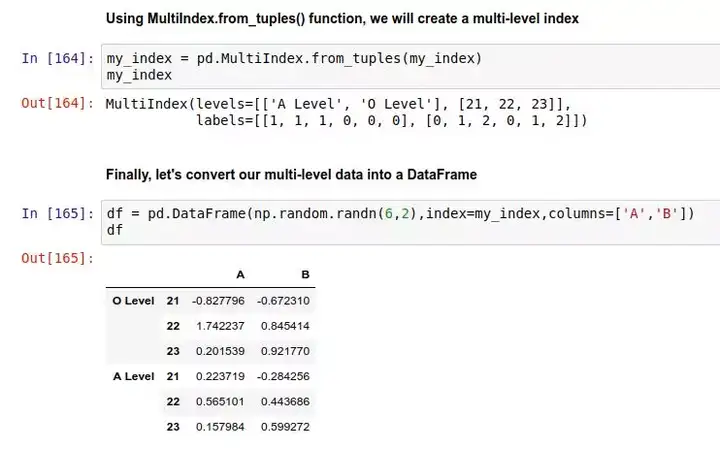
最后,将这个多级索引对象转成一个 DataFrame:
要获取多级索引中的数据,还是用到 .loc[] 。比如,先获取 'O Level' 下的数据:
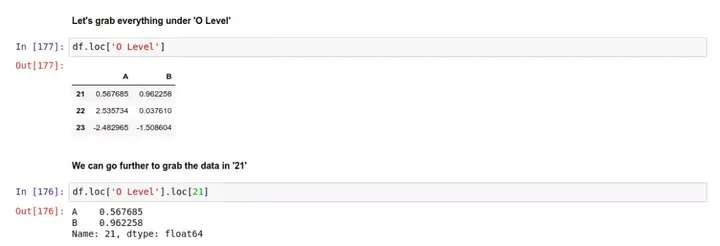
然后再用一次 .loc[],获取下一层 21 里的数据:
如上所示,df 这个 DataFrame 的头两个索引列没有名字,看起来不太易懂。我们可以用.index.names 给它们加上名字:

交叉选择行和列中的数据
我们可以用 .xs() 方法轻松获取到多级索引中某些特定级别的数据。比如,我们需要找到所有 Levels 中,Num = 22 的行:

清洗数据
删除或填充空值
在许多情况下,如果你用 Pandas 来读取大量数据,往往会发现原始数据中会存在不完整的地方。在 DataFrame 中缺少数据的位置, Pandas 会自动填入一个空值,比如 NaN或 Null 。因此,我们可以选择用 .dropna() 来丢弃这些自动填充的值,或是用.fillna() 来自动给这些空值填充数据。
比如这个例子:
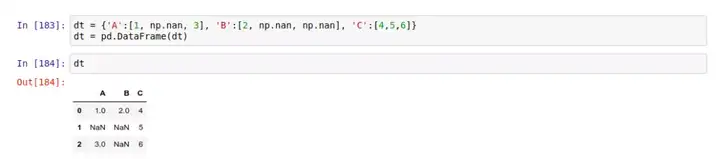
当你使用 .dropna() 方法时,就是告诉 Pandas 删除掉存在一个或多个空值的行(或者列)。删除列用的是 .dropna(axis=0) ,删除行用的是 .dropna(axis=1) 。
请注意,如果你没有指定 axis 参数,默认是删除行。
删除行:
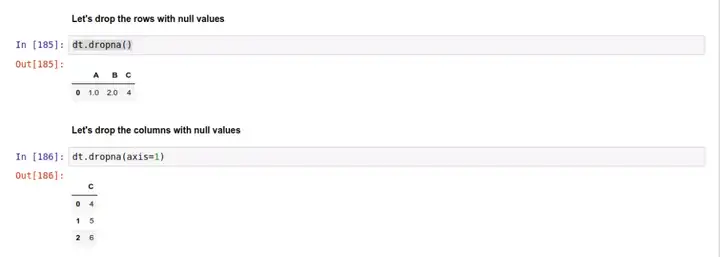
删除列:
类似的,如果你使用 .fillna() 方法,Pandas 将对这个 DataFrame 里所有的空值位置填上你指定的默认值。比如,将表中所有 NaN 替换成 20 :

当然,这有的时候打击范围太大了。于是我们可以选择只对某些特定的行或者列进行填充。比如只对 'A' 列进行操作,在空值处填入该列的平均值:

如上所示,'A' 列的平均值是 2.0,所以第二行的空值被填上了 2.0。
同理,.dropna() 和 .fillna() 并不会永久性改变你的数据,除非你传入了inplace=True 参数。
上篇完结,下篇会有更多干货等着大家,敬请期待。
知乎机构号:来自硅谷的终身学习平台——优达学城(http://Udacity.com),专注于技能提升和求职法则,让你在家能追随 Google、Facebook、IBM 等行业大佬,从零开始掌握数据分析、机器学习、深度学习、人工智能、无人驾驶等前沿技术,激发未来无限可能!