Pandas 是基于 NumPy 的一个开源 Python 库,它被广泛用于快速分析数据,以及数据清洗和准备等工作。它的名字来源是由“ Panel data”(面板数据,一个计量经济学名词)两个单词拼成的。简单地说,你可以把 Pandas 看作是 Python 版的 Excel。
我喜欢 Pandas 的原因之一,是因为它很酷,它能很好地处理来自一大堆各种不同来源的数据,比如 Excel 表格、CSV 文件、SQL 数据库,甚至还能处理存储在网页上的数据。
上篇回顾:30分钟带你入门数据分析工具 Pandas(上篇),果断收藏!今晚发布的为下篇。希望对大家有帮助。
分组统计
Pandas 的分组统计功能可以按某一列的内容对数据行进行分组,并对其应用统计函数,比如求和,平均数,中位数,标准差等等…
举例来说,用 .groupby() 方法,我们可以对下面这数据表按 'Company' 列进行分组,并用 .mean() 求每组的平均值:
首先,初始化一个DataFrame:
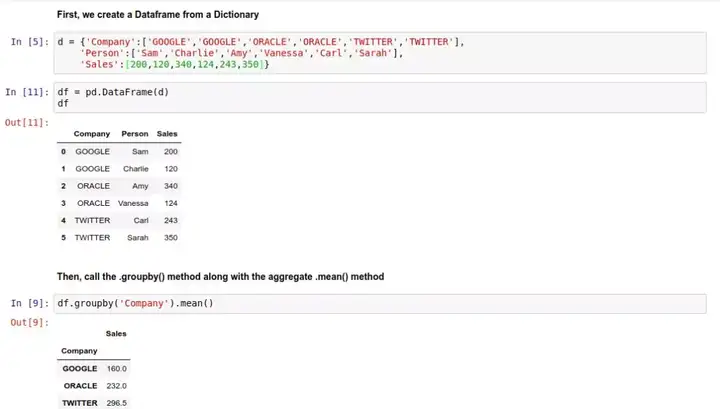
然后,调用 .groupby() 方法,并继续用 .mean() 求平均值:
上面的结果中,Sales 列就变成每个公司的分组平均数了。
计数
用 .count() 方法,能对 DataFrame 中的某个元素出现的次数进行计数。

数据描述
Pandas 的 .describe() 方法将对 DataFrame 里的数据进行分析,并一次性生成多个描述性的统计指标,方便用户对数据有一个直观上的认识。
生成的指标,从左到右分别是:计数、平均数、标准差、最小值、25% 50% 75% 位置的值、最大值。

如果你不喜欢这个排版,你可以用 .transpose() 方法获得一个竖排的格式:
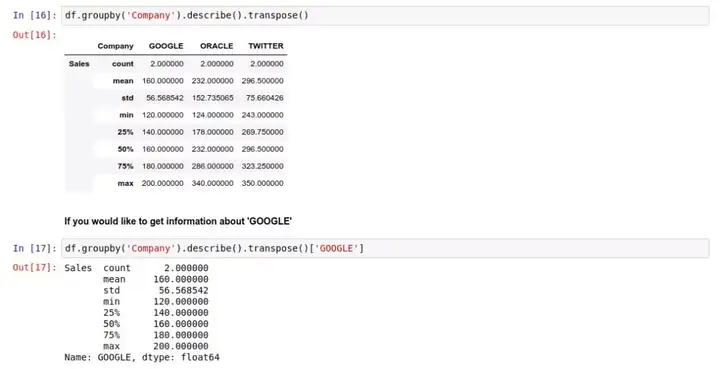
如果你只想看 Google 的数据,还能这样:
堆叠(Concat)
堆叠基本上就是简单地把多个 DataFrame 堆在一起,拼成一个更大的 DataFrame。当你进行堆叠的时候,请务必注意你数据表的索引和列的延伸方向,堆叠的方向要和它一致。
比如,有这样3个 DataFrame:
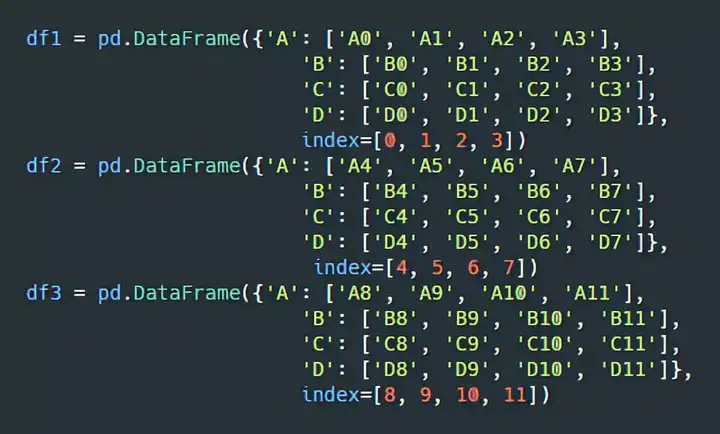
我们用 pd.concat() 将它堆叠成一个大的表:
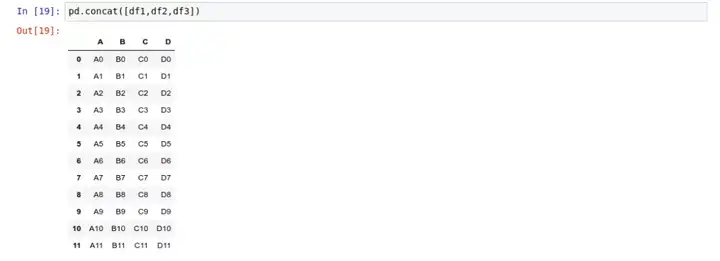
因为我们没有指定堆叠的方向,Pandas 默认按行的方向堆叠,把每个表的索引按顺序叠加。
如果你想要按列的方向堆叠,那你需要传入 axis=1 参数:
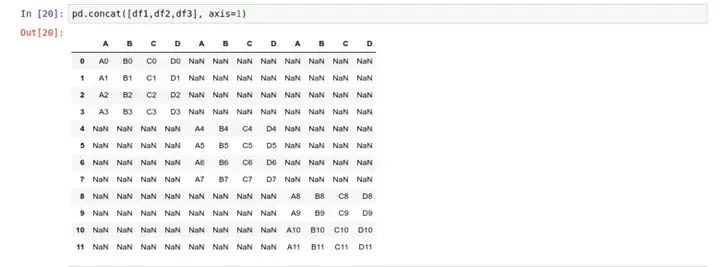
注意,这里出现了一大堆空值。因为我们用来堆叠的3个 DataFrame 里,有许多索引是没有对应数据的。因此,当你使用 pd.concat() 的时候,一定要注意堆叠方向的坐标轴(行或列)含有所需的所有数据。
归并(Merge)
使用 pd.merge() 函数,能将多个 DataFrame 归并在一起,它的合并方式类似合并 SQL 数据表的方式。
归并操作的基本语法是 pd.merge(left, right, how='inner', on='Key') 。其中 left 参数代表放在左侧的 DataFrame,而 right 参数代表放在右边的 DataFrame;how='inner' 指的是当左右两个 DataFrame 中存在不重合的 Key 时,取结果的方式:inner 代表交集;Outer 代表并集。最后,on='Key' 代表需要合并的键值所在的列,最后整个表格会以该列为准进行归并。
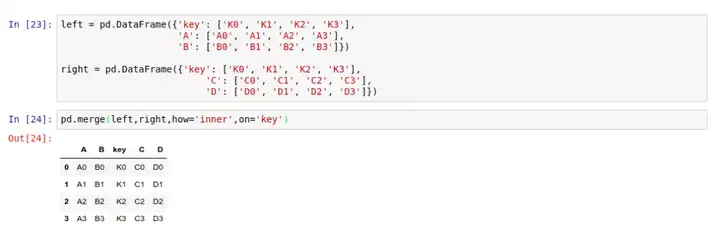
对于两个都含有 key 列的 DataFrame,我们可以这样归并:
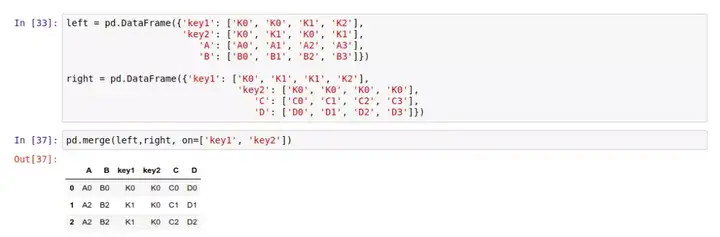
同时,我们可以传入多个 on 参数,这样就能按多个键值进行归并:
连接(Join)
如果你要把两个表连在一起,然而它们之间没有太多共同的列,那么你可以试试 .join() 方法。和 .merge() 不同,连接采用索引作为公共的键,而不是某一列。
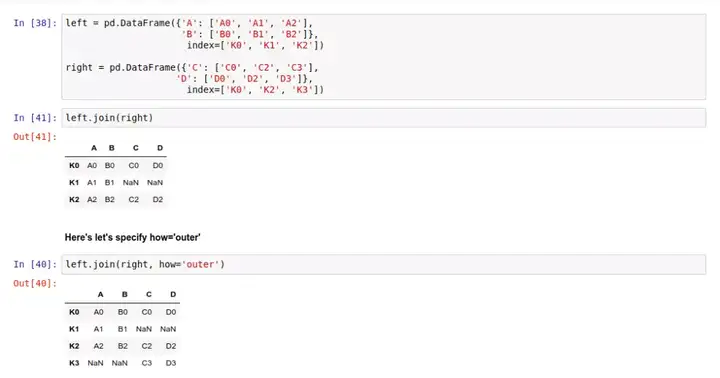
同样,inner 代表交集,Outer 代表并集。
数值处理
- 查找不重复的值
不重复的值,在一个 DataFrame 里往往是独一无二,与众不同的。找到不重复的值,在数据分析中有助于避免样本偏差。在 Pandas 里,主要用到 3 种方法:
首先是 .unique() 方法。比如在下面这个 DataFrame 里,查找 col2 列中所有不重复的值:
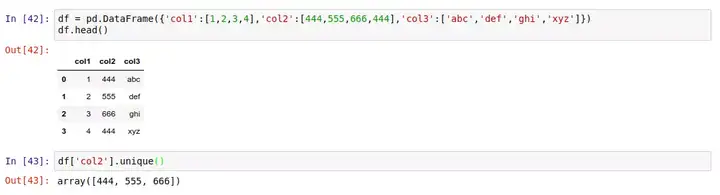
除了列出所有不重复的值,我们还能用 .nunique() 方法,获取所有不重复值的个数:

此外,还可以用 .value_counts() 同时获得所有值和对应值的计数:

- apply() 方法
用 .apply() 方法,可以对 DataFrame 中的数据应用自定义函数,进行数据处理。比如,我们先定义一个 square() 函数,然后对表中的 col1 列应用这个函数:
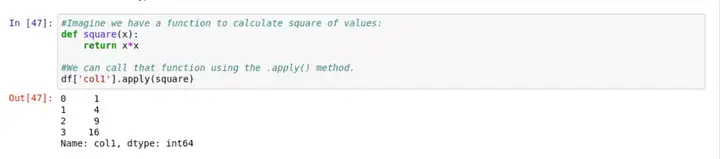
在上面这个例子中,这个函数被应用到这一列里的每一个元素上。同样,我们也可以调用任意的内置函数。比如对 col3 列取长度 len :

有的时候,你定义了一个函数,而它其实只会被用到一次。那么,我们可以用 lambda 表达式来代替函数定义,简化代码。比如,我们可以用这样的 lambda 表达式代替上面 In[47] 里的函数定义:

- 获取 DataFrame 的属性
DataFrame 的属性包括列和索引的名字。假如你不确定表中的某个列名是否含有空格之类的字符,你可以通过 .columns 来获取属性值,以查看具体的列名。

排序
如果想要将整个表按某一列的值进行排序,可以用 .sort_values() :

如上所示,表格变成按 col2 列的值从小到大排序。要注意的是,表格的索引 index 还是对应着排序前的行,并没有因为排序而丢失原来的索引数据。
查找空值
假如你有一个很大的数据集,你可以用 Pandas 的 .isnull() 方法,方便快捷地发现表中的空值。

这返回的是一个新的 DataFrame,里面用布尔值(True/False)表示原 DataFrame 中对应位置的数据是否是空值。
数据透视表
在使用 Excel 的时候,你或许已经试过数据透视表的功能了。数据透视表是一种汇总统计表,它展现了原表格中数据的汇总统计结果。Pandas 的数据透视表能自动帮你对数据进行分组、切片、筛选、排序、计数、求和或取平均值,并将结果直观地显示出来。比如,这里有个关于动物的统计表:
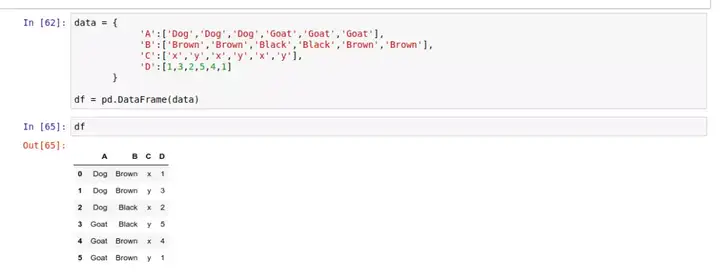
Pandas 数据透视表的语法是 .pivot_table(data, values='', index=[''], columns=['']) ,其中 values 代表我们需要汇总统计的数据点所在的列,index 表示按该列进行分组索引,而 columns 则表示最后结果将按该列的数据进行分列。你可以在 Pandas 的官方文档 中找到更多数据透视表的详细用法和例子。
于是,我们按上面的语法,给这个动物统计表创建一个数据透视表:
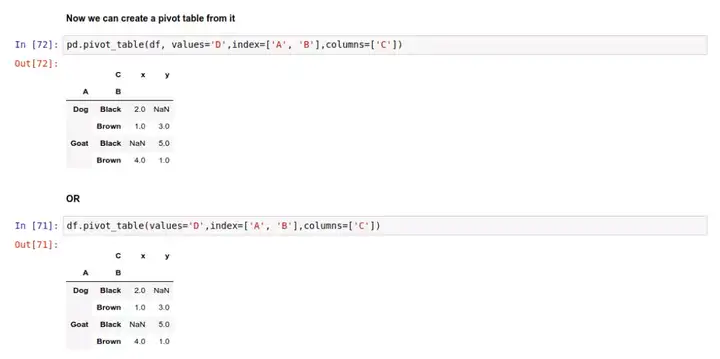
或者也可以直接调用 df 对象的方法:
在上面的例子中,数据透视表的某些位置是 NaN 空值,因为在原数据里没有对应的条件下的数据。
导入导出数据
采用类似 pd.read_ 这样的方法,你可以用 Pandas 读取各种不同格式的数据文件,包括 Excel 表格、CSV 文件、SQL 数据库,甚至 HTML 文件等。
- 读取 CSV 文件
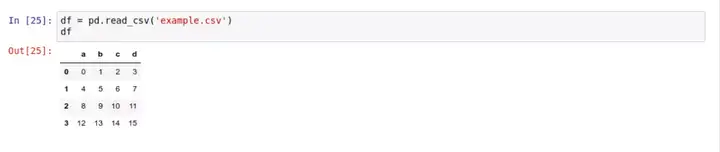
简单地说,只要用 pd.read_csv() 就能将 CSV 文件里的数据转换成 DataFrame 对象:
- 写入 CSV 文件
将 DataFrame 对象存入 .csv 文件的方法是 .to_csv(),例如,我们先创建一个 DataFrame 对象:
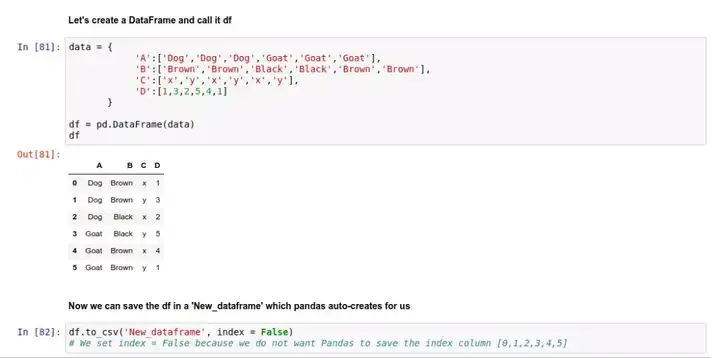
然后我们将这个 DataFrame 对象存成 'New_dataframe' 文件,Pandas 会自动在磁盘上创建这个文件。
这里传入 index=False 参数是因为不希望 Pandas 把索引列的 0~5 也存到文件中。
为了确保数据已经保存好了,你可以试试用 pd.read_csv('New_dataframe') ,把这个文件的内容读取出来看看。
读取 Excel 表格文件
Excel 文件是一个不错的数据来源。使用 pd.read_excel() 方法,我们能将 Excel 表格中的数据导入 Pandas 中。请注意,Pandas 只能导入表格文件中的数据,其他对象,例如宏、图形和公式等都不会被导入。如果文件中存在有此类对象,可能会导致 pd.read_excel() 方法执行失败。
举个例子,假设我们有一个 Excel 表格 'excel_output.xlsx',然后读取它的数据:
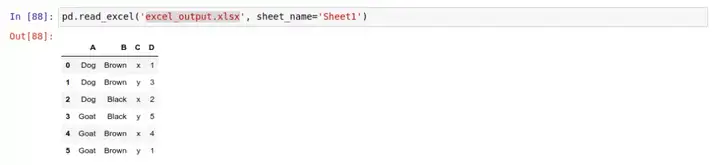
请注意,每个 Excel 表格文件都含有一个或多个工作表,传入 sheet_name='Sheet1' 这样的参数,就表示只读取 'excel_output.xlsx' 中的 Sheet1 工作表中的内容。
写入 Excel 表格文件
跟写入 CSV 文件类似,我们可以将一个 DataFrame 对象存成 .xlsx 文件,语法是 .to_excel() :
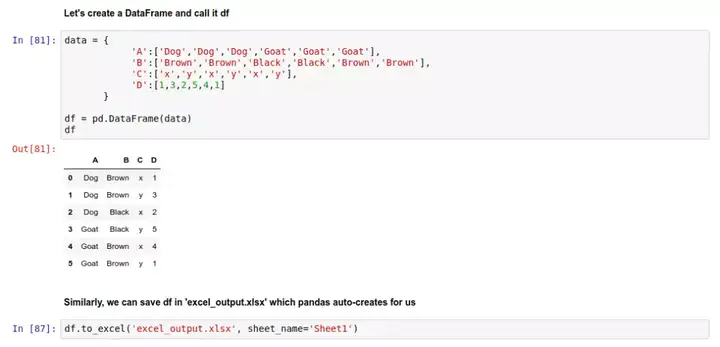
和前面类似,把数据存到 'excel_output.xlsx' 文件中:
读取 HTML 文件中的数据
为了读取 HTML 文件,你需要安装 htmllib5,lxml 以及 BeautifulSoup4 库,在终端或者命令提示符运行以下命令来安装:
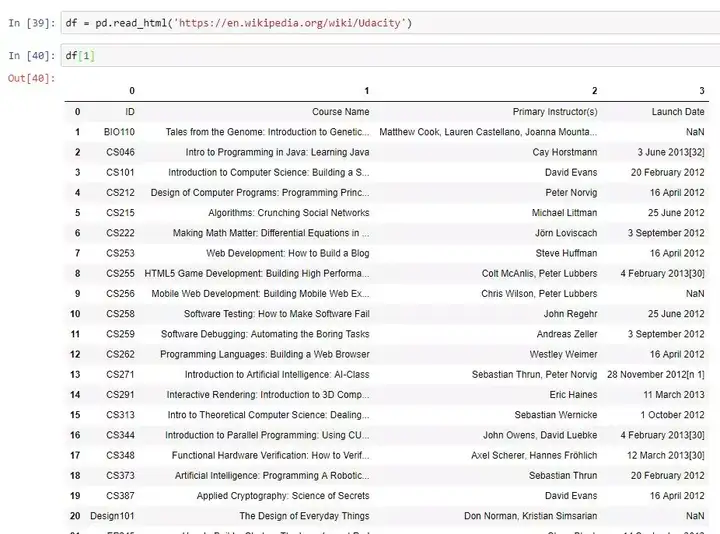
举个例子,我们用让 Pandas 读取这个页面的数据: https://en.wikipedia.org/wiki/Udacity 。由于一个页面上含有多个不同的表格,我们需要通过下标 [0, ..., len(tables) - 1] 访问数组中的不同元素。
下面的这个例子,我们显示的是页面中的第 2 个表格:
结语
恭喜!读到这里,说明你已经看完了这个教程!
如果你已经学完了本文,我想你应该已经拥有足够的知识,可以好好调教 Pandas,做好分析之前的数据准备工作啦。接下来,你需要的是练习,练习,再练习!
祝你的数据分析之旅顺利!
作者: Ehi Aigiomawu
编译: 欧剃