写在前面:本文仅是自己的学习笔记,还有待完善的地方,如有不当,还请指正。【侵删】
解决机器学习问题花费的很多心思都是在准备数据上。为了让你的代码可读性更高,Pytorch提供了很多让加载数据更简单的工具。在这个教程中,我们将看到如何对不一般的数据进行加载和预处理/数据增强。
为了能够运行教程中的例子,请确保你已经安装了下面的包:
- scikit-image:需要io和transforms
- pandas:操作csv文件更方便
(译者注:先导入我们接下来所需要的库)
from __future__ import print_function, division
import os
import torch
import pandas as pd
from skimage import io, transform
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
# 忽略warnings
import warnings
warnings.filterwarnings("ignore")
plt.ion() # 开启交互模式
我们接下来将要处理的是面部姿势数据集。这意味着一张脸做了这样的标注:

每张脸的图像总共有68个不同的标记点。
Note:
为了让图片以‘faces/’的文件夹命名,请从这里下载数据集。这份数据是从ImageNet中选取一些标记为‘face’的图片,使用 dlib’s pose estimation方法生成的。
数据集里面有一份标注的csv文件,像这样:
image_name,part_0_x,part_0_y,part_1_x,part_1_y,part_2_x, ... ,part_67_x,part_67_y
0805personali01.jpg,27,83,27,98, ... 84,134
1084239450_e76e00b7e7.jpg,70,236,71,257, ... ,128,312
让我们快速的读取CSV文件,以(N,2)的数组形式获得标记点,其中N表示标记点的个数。
landmarks_frame = pd.read_csv('faces/face_landmarks.csv')
n = 65
img_name = landmarks_frame.ix[n, 0]
landmarks = landmarks_frame.ix[n, 1:].as_matrix().astype('float')
landmarks = landmarks.reshape(-1, 2)
print('Image name: {}'.format(img_name))
print('Landmarks shape: {}'.format(landmarks.shape))
print('First 4 Landmarks: {}'.format(landmarks[:4]))
输出:
Image name: person-7.jpg
Landmarks shape: (68, 2)
First 4 Landmarks: [[ 32. 65.]
[ 33. 76.]
[ 34. 86.]
[ 34. 97.]]
我们先写一个可以显示一张图片和它的标记点的函数,然后可以用它来显示一个样本。
def show_landmarks(image, landmarks):
"""显示带标记点的图片"""
plt.imshow(image)
plt.scatter(landmarks[:, 0], landmarks[:, 1], s=10, marker='.', c='r')
plt.pause(0.001)
plt.figure()
show_landmarks(io.imread(os.path.join('faces/', img_name)),
landmarks)
plt.show()

Dataset类
torch.utils.data.Dataset是一个表示数据集的抽象类。自己的数据集需要继承Dataset这个类,然后再重写下面的方法:
- __len__ 使len(dataset)返回数据集的大小
- __getitem__ 支持地址索引,使得dataset[i]可以获取第i个样本
我们创建一个人脸标记点数据的类。把读取csv文件的工作放在了__init__中,而将读取图片的任务放在了__getitem__里。这样做可以充分利用内存,因为图片不需要一下子全部读取内存,而是按需读取(译者注:读取一批)。
我们的数据集是以{'image': image, 'landmarks': landmarks}的字典形式存储的。数据集的类有一个可选的参数transform,这样就可以对数据做特定的预处理操作。在下一节中我们会看到transfrom的作用。
class FaceLandmarksDataset(Dataset):
"""人脸标记点数据"""
def __init__(self, csv_file, root_dir, transform=None):
"""
参数:
csv_file (字符串): 标记点csv文件的路径。
root_dir (字符串): 图片的字典。
transform (callable, 可选): 可选的transform操作。
"""
self.landmarks_frame = pd.read_csv(csv_file)
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.landmarks_frame)
def __getitem__(self, idx):
img_name = os.path.join(self.root_dir, self.landmarks_frame.ix[idx, 0])
image = io.imread(img_name)
landmarks = self.landmarks_frame.ix[idx, 1:].as_matrix().astype('float')
landmarks = landmarks.reshape(-1, 2)
sample = {'image': image, 'landmarks': landmarks}
if self.transform:
sample = self.transform(sample)
return sample
让我们实例化这个类,并且遍历所有的数据样本。我们将打印前4个样本的形状,显示他们的标记点。
face_dataset = FaceLandmarksDataset(csv_file='faces/face_landmarks.csv',
root_dir='faces/')
fig = plt.figure()
for i in range(len(face_dataset)):
sample = face_dataset[i]
print(i, sample['image'].shape, sample['landmarks'].shape)
ax = plt.subplot(1, 4, i + 1)
plt.tight_layout()
ax.set_title('Sample #{}'.format(i))
ax.axis('off')
show_landmarks(**sample) # 1
if i == 3:
plt.show()
break
(译者注:# 1 **表示接收字典参数)

输出:
0 (324, 215, 3) (68, 2)
1 (500, 333, 3) (68, 2)
2 (250, 258, 3) (68, 2)
3 (434, 290, 3) (68, 2)
Transforms
从上面的输出中我们可以发现样本的尺寸大小不一致。而大部分的神经网络都要求图片以固定的尺寸输入网络。因此,我们需要写个预处理函数。我们创建三个transforms:
- Rescale:修改图片尺寸
- RandomCrop:随机裁剪图片。数据增强方法
- ToTensor:将图片从numpy格式转为torch(我们需要交换维度)
我们把它们写成可以调用的类而不是简单的函数,这样每次只需要传递需要的参数就可以调用transforms函数了。这样的话,我们就需要完成__call__方法以及__init__,如果需要这个的话。之后我们就可以像这样使用transforms了:
tsfm = Transform(params)
transformed_sample = tsfm(sample)
仔细观察下面的函数是如何同时对图片和标记点做transforms的。
class Rescale(object):
"""将样本中图片修改为规定的尺寸.
参数:
output_size (init 或者 tuple): 要求的输出尺寸. 如果是tuple, 输出和output_size匹配。
如果是int, 图片的短边是output_size,长边按比例缩放。
"""
def __init__(self, output_size):
assert isinstance(output_size, (int, tuple))
self.output_size = output_size
def __call__(self, sample):
image, landmarks = sample['image'], sample['landmarks']
h, w = image.shape[:2]
if isinstance(self.output_size, int):
if h > w:
new_h, new_w = self.output_size * h / w, self.output_size
else:
new_h, new_w = self.output_size, self.output_size * w / h
else:
new_h, new_w = self.output_size
new_h, new_w = int(new_h), int(new_w)
img = transform.resize(image, (new_h, new_w))
# 对landmarks来说h和w需要交换位置,因为对图片来说,x和y分别是第1维和第0维
landmarks = landmarks * [new_w / w, new_h / h]
return {'image': img, 'landmarks': landmarks}
class RandomCrop(object):
"""随机裁剪图片.
参数:
output_size (tuple or int): 期望的输出尺寸. 如果是int, 做正方形裁剪.
"""
def __init__(self, output_size):
assert isinstance(output_size, (int, tuple))
if isinstance(output_size, int):
self.output_size = (output_size, output_size)
else:
assert len(output_size) == 2
self.output_size = output_size
def __call__(self, sample):
image, landmarks = sample['image'], sample['landmarks']
h, w = image.shape[:2]
new_h, new_w = self.output_size
top = np.random.randint(0, h - new_h)
left = np.random.randint(0, w - new_w)
image = image[top: top + new_h,
left: left + new_w]
landmarks = landmarks - [left, top]
return {'image': image, 'landmarks': landmarks}
class ToTensor(object):
"""将ndarrays转化为Tensors."""
def __call__(self, sample):
image, landmarks = sample['image'], sample['landmarks']
# 交换颜色通道,因为
# numpy图片: H x W x C
# torch图片: C X H X W
image = image.transpose((2, 0, 1))
return {'image': torch.from_numpy(image),
'landmarks': torch.from_numpy(landmarks)}
Compose transforms
现在我们就将transform运用在一个样本上。
我们说我们想将图片的短边变为256,之后随机裁剪一个边长为224的正方形。这样的话,我们就需要组合Rescale和RandomCrop了。
scale = Rescale(256)
crop = RandomCrop(128)
composed = transforms.Compose([Rescale(256),
RandomCrop(224)])
# 对样本进行上面的每一个操作.
fig = plt.figure()
sample = face_dataset[65]
for i, tsfrm in enumerate([scale, crop, composed]):
transformed_sample = tsfrm(sample)
ax = plt.subplot(1, 3, i + 1)
plt.tight_layout()
ax.set_title(type(tsfrm).__name__)
show_landmarks(**transformed_sample)
plt.show()
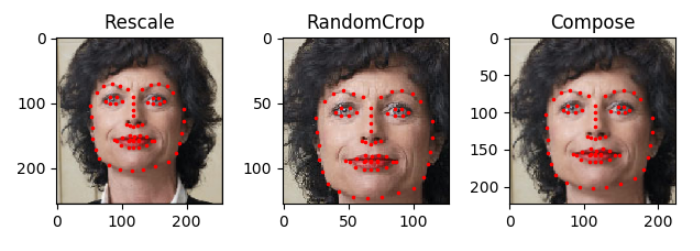
(译者注:左图是scale操作,中图是crop操作,右图是composed操作)
迭代数据
我们将所有的放在一起来生成composed transforms之后的数据。总之,每次迭代的数据:
- 从文件中读取一幅图像
- 在读取图片时进行transforms操作
- 由于其中一个transforms是随机的,所以迭代的数据样本进行了增强
我们可以像之前一样使用for i in range循环从创建的数据中进行迭代。
transformed_dataset = FaceLandmarksDataset(csv_file='faces/face_landmarks.csv',
root_dir='faces/',
transform=transforms.Compose([
Rescale(256),
RandomCrop(224),
ToTensor()
]))
for i in range(len(transformed_dataset)):
sample = transformed_dataset[i]
print(i, sample['image'].size(), sample['landmarks'].size())
if i == 3:
break
输出:
0 torch.Size([3, 224, 224]) torch.Size([68, 2])
1 torch.Size([3, 224, 224]) torch.Size([68, 2])
2 torch.Size([3, 224, 224]) torch.Size([68, 2])
3 torch.Size([3, 224, 224]) torch.Size([68, 2])
然而,通过使用一个简单的for循环来迭代数据我们可能损失很多信息。尤其是我们丢失了这些操作:
- 按批读取数据
- 打乱数据顺序
- 使用多进程(multiprocessing)并行加载数据
torch.utils.data.DataLoader是一个提供上面所有信息的迭代器。下面使用的参数应该很清晰。其中一个蛮有趣的参数是collate_fn。你可以使用collate_fn来指定如何读取一批的额样本。然而,默认的collate在大部分的情况下都表现得很好。
dataloader = DataLoader(transformed_dataset, batch_size=4,
shuffle=True, num_workers=4)
# 显示一批的数据
def show_landmarks_batch(sample_batched):
"""显示一批样本的图片和标记点."""
images_batch, landmarks_batch = \
sample_batched['image'], sample_batched['landmarks']
batch_size = len(images_batch)
im_size = images_batch.size(2)
grid = utils.make_grid(images_batch)
plt.imshow(grid.numpy().transpose((1, 2, 0)))
for i in range(batch_size):
plt.scatter(landmarks_batch[i, :, 0].numpy() + i * im_size,
landmarks_batch[i, :, 1].numpy(),
s=10, marker='.', c='r')
plt.title('Batch from dataloader')
for i_batch, sample_batched in enumerate(dataloader):
print(i_batch, sample_batched['image'].size(),
sample_batched['landmarks'].size())
# 观察到第4批的时候就停止.
if i_batch == 3:
plt.figure()
show_landmarks_batch(sample_batched)
plt.axis('off')
plt.ioff() # 1
plt.show()
break
(译者注:#1 显示前关掉交互模式)

输出结果:
0 torch.Size([4, 3, 224, 224]) torch.Size([4, 68, 2])
1 torch.Size([4, 3, 224, 224]) torch.Size([4, 68, 2])
2 torch.Size([4, 3, 224, 224]) torch.Size([4, 68, 2])
3 torch.Size([4, 3, 224, 224]) torch.Size([4, 68, 2])
后记:torchvision
这这个教程里,我们已经学会如何写并且使用datasets, transforms 和 dataloader。torchvision提供了一些常用的数据集和transforms。你甚至就不必写自定义的类。在torchvision中一个最经常用的数据集是ImageFolder。它要求数据按下面的形式存放:
root/ants/xxx.png
root/ants/xxy.jpeg
root/ants/xxz.png
.
.
.
root/bees/123.jpg
root/bees/nsdf3.png
root/bees/asd932_.png
其中,‘ants’, ‘bees’等是类别。对PIL.Image进行的通用的transforms操作如RandomHorizontalFlip, Scale也可以随时使用。你可以像这样使用这样函数来写dataloader:
import torch
from torchvision import transforms, datasets
data_transform = transforms.Compose([
transforms.RandomSizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
hymenoptera_dataset = datasets.ImageFolder(root='hymenoptera_data/train',
transform=data_transform)
dataset_loader = torch.utils.data.DataLoader(hymenoptera_dataset,
batch_size=4, shuffle=True,
num_workers=4)
关于训练代码的例子,请看【译】pytorch迁移学习(原文: Transfer Learning tutorial)
怎能忘本,原文在这里。